Understanding Consistent Hashing Through a Real Redis + Java Lab
Why Consistent Hashing Exists
One of the most common ways engineers initially distribute data across cache nodes is:
hash(key) % NWhere:
key= cache keyN= total number of nodes
At first glance, it seems perfect:
- simple
- fast
- deterministic
- horizontally scalable
But distributed systems are not difficult because of normal operation.
They are difficult because systems constantly change.
Nodes fail.
Clusters scale.
Infrastructure evolves.
And that is where the real problem begins.
The Real Problem is NOT Distribution
The difficult part is not distributing data.
The difficult part is:
redistributing data when the cluster changesTo deeply understand this problem, I built a small hands-on lab using:
- Java + Spring Boot
- Multiple Redis instances
- Manual cache sharding
- Hash-based routing
- Docker
The Initial Architecture
I started with 3 Redis nodes:
redis-1 -> localhost:6379
redis-2 -> localhost:6380
redis-3 -> localhost:6381The Spring Boot application acted as a cache router.
Every key was routed using:
hash(key) % totalNodesExample:
int index = Math.floorMod(hash, redisNodes.size());Then the application selected the corresponding Redis instance.
Running Redis Nodes with Docker
docker run -d --name redis-1 -p 6379:6379 redis:7
docker run -d --name redis-2 -p 6380:6379 redis:7
docker run -d --name redis-3 -p 6381:6379 redis:7Java Cache Router Service
The application used MD5 hashing to generate a stable hash from the cache key.
private int getNodeIndex(String key) {
int hash = stableHash(key);
return Math.floorMod(hash, redisNodes.size());
}The selected node was then used for cache operations:
redisNodes.get(index).set(key, value);and:
redisNodes.get(index).get(key);Full Cache Router Service
package redis_sharding_lab.demo.service;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.List;
import java.util.Map;
@Service
public class CacheRouterService {
private final List<Jedis> redisNodes = List.of(
new Jedis("localhost", 6379),
new Jedis("localhost", 6380),
new Jedis("localhost", 6381)
);
private final List<String> nodeNames = List.of(
"redis-1",
"redis-2",
"redis-3"
);
public Map<String, Object> set(String key, String value) {
System.out.println("\n========== SET REQUEST ==========");
System.out.println("Incoming key: " + key);
System.out.println("Incoming value: " + value);
int index = getNodeIndex(key);
System.out.println("Selected Redis node: " + nodeNames.get(index));
System.out.println("Saving value into Redis...");
redisNodes.get(index).set(key, value);
System.out.println("Value successfully stored.");
return Map.of(
"key", key,
"value", value,
"node", nodeNames.get(index),
"nodeIndex", index
);
}
public Map<String, Object> get(String key) {
System.out.println("\n========== GET REQUEST ==========");
System.out.println("Searching key: " + key);
int index = getNodeIndex(key);
System.out.println("Selected Redis node: " + nodeNames.get(index));
System.out.println("Fetching value from Redis...");
String value = redisNodes.get(index).get(key);
if (value == null) {
System.out.println("CACHE MISS");
} else {
System.out.println("CACHE HIT");
System.out.println("Returned value: " + value);
}
return Map.of(
"key", key,
"value", value == null ? "MISS" : value,
"node", nodeNames.get(index),
"nodeIndex", index
);
}
private int getNodeIndex(String key) {
int hash = stableHash(key);
System.out.println("Generated hash: " + hash);
System.out.println("hash % totalNodes = " + hash + " % " + redisNodes.size());
int index = Math.floorMod(hash, redisNodes.size());
System.out.println("Calculated node index: " + index);
return index;
}
private int stableHash(String key) {
try {
System.out.println("Generating MD5 hash for key: " + key);
MessageDigest digest = MessageDigest.getInstance("MD5");
byte[] bytes = digest.digest(key.getBytes(StandardCharsets.UTF_8));
int hash = 0;
for (int i = 0; i < 4; i++) {
hash = (hash << 8) | (bytes[i] & 0xff);
}
System.out.println("Final generated hash: " + hash);
return hash;
} catch (Exception e) {
throw new RuntimeException("Error hashing key", e);
}
}
}Example Flow
Request:
POST /cache/user:1?value=EduardoInternal flow:
user:1
↓
MD5 hash
↓
hash % 3
↓
redis-3Result:
SET user:1 Eduardoinside redis-3.
Generating Test Data
I generated 100 cache entries:
for i in {1..100}; do
curl -X POST "http://localhost:8080/cache/user:$i?value=user-$i"
doneThen I queried all keys:
for i in {1..100}; do
curl "http://localhost:8080/cache/user:$i"
doneEvery request returned:
CACHE HITThe logs showed correct distribution:
user:1 -> redis-3
user:4 -> redis-2
user:5 -> redis-1
user:10 -> redis-1Everything worked perfectly.
The Critical Experiment
Then I added a fourth Redis node:
docker run -d --name redis-4 -p 6382:6379 redis:7and updated the application:
new Jedis("localhost", 6382)Now:
N = 3 -> N = 4Without touching the existing data.
Suddenly: Massive Cache Misses
After rerunning the same GET requests:
CACHE MISS
CACHE MISS
CACHE MISSappeared everywhere.
Why Did This Happen?
The important part:
The hash itself never changed.
Example:
hash(user:1) = -1112417008Before:
floorMod(hash, 3) = 2 -> redis-3After:
floorMod(hash, 4) = 0 -> redis-1The data still physically existed in:
redis-3But the router now searched in:
redis-1Result:
CACHE MISSThe Core Problem with hash(key) % N
Modulo hashing tightly couples data placement to the number of nodes.
That means:
changing N changes key mappingAdding or removing a node can remap a huge percentage of keys.
Why This is Dangerous in Production
In real systems, this can create:
- massive cache misses
- database overload
- latency spikes
- expensive rebalancing
- avalanche-like behavior
Imagine millions of requests suddenly bypassing cache and hitting the database.
This is exactly why distributed caching becomes challenging at scale.
Cache Avalanche-Like Behavior
This experiment also demonstrated something interesting.
The issue behaved similarly to:
Cache Avalanchebecause:
many keys
→ started failing simultaneously
→ causing potential DB traffic spikesThis was not caused by TTL expiration.
It was caused by:
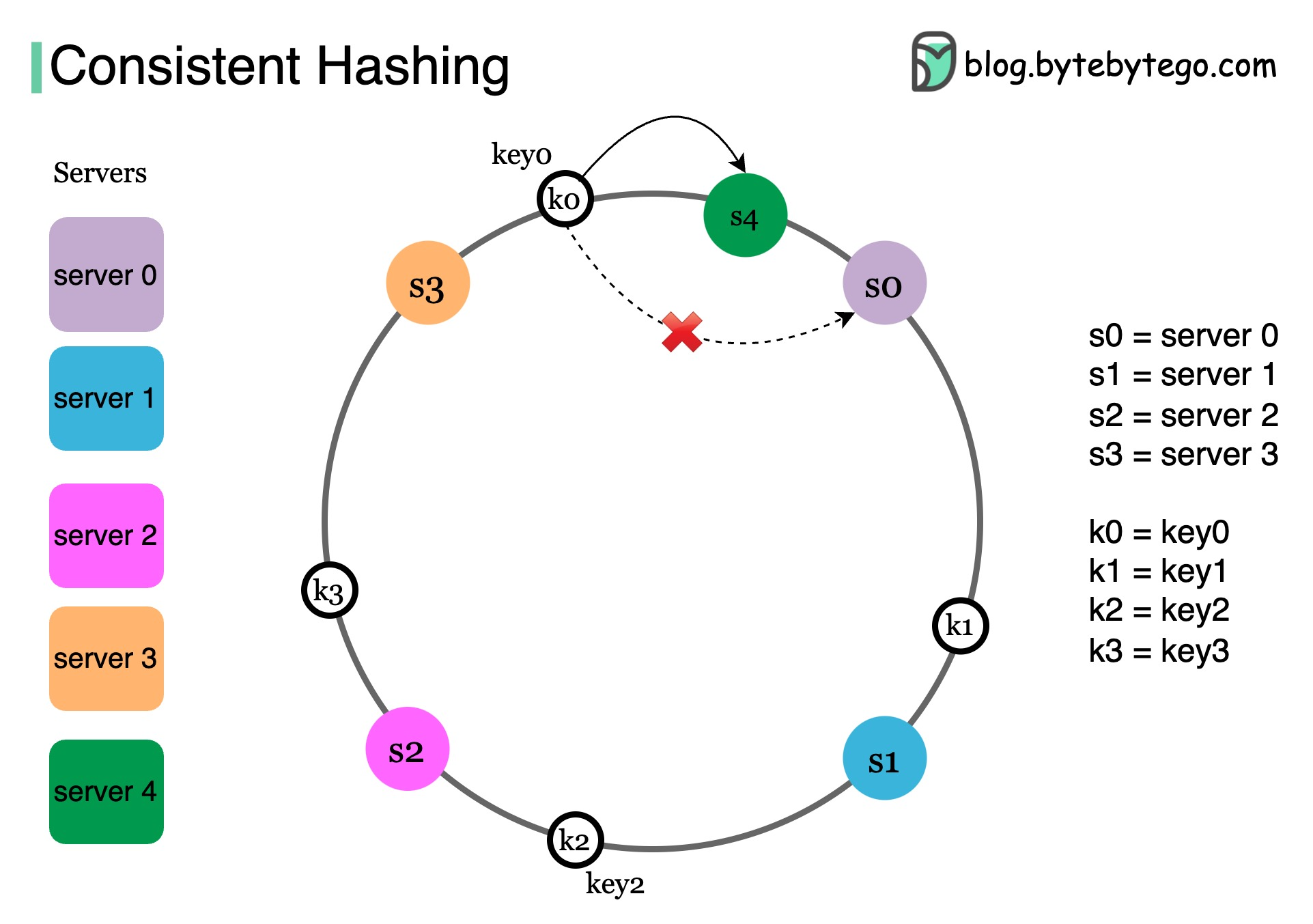
cluster topology changeEnter Consistent Hashing
Work in progress 🚧